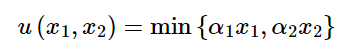おんなじだお!もはや日本語で書いてもらえないんだお。伴って変化する二つがあるといきなりこういう記号を読まされる。これは「 t がほんの少し増えたとき、f がその何倍増えるか」です。こちらの記号で書かれている場合は、tがほんの少し増えたとき、数式上明確になっているfの増分だけでなく、たとえばtが増えたせいでxもいくらか増えていて、xがいくらか増えたせいでfがいくらか増えるぶんも全部計上してあげないといけません。
中学生の頃から数学が得意な君たちは「等積変形」をして、y を x の「関数のように書く」ことができるね。でもね、「関数のように書く」という作業が終わったとたん、やっていいとは限らないのが「だからyは x の関数です」と定義することだよね。関数であるためには、x に対して y が一意に決まらないといけなかったよね。また連続関数だったり、微分可能だったりすることは、どうやって保障されるんだろうな。
G 0.872
Z 0.86
X 0.814
V 0.804
W 0.798
K 0.732
B 0.608
R 0.6
A 0.574
こんな感じでしたね。
V F Q X Z
上の文字列は確率論の計算であれば15%の確率で五文字すべて強そうに見えることになるのですが(詳細略)。しかし実際にすべて強そうに見えたひとの割合は7%でした。組まされると弱く見えてくるアルファベットがいるわけです。
B G Z T A
上の文字列も確率論の計算であれば12%の確率で五文字すべて強そうに見えることになるのですが(詳細略)。しかし実際にすべて強そうに見えたひとの割合は8%でした。やはり組まされると弱く見えてくるアルファベットがいるわけです。
「はい」の割合は左から何番目であるかに大きく影響しませんでした。全体であれば5つの位置についておよそ50%前後で大きな違いはありませんでした(詳細略)。しかし、
Fが強そうにみえた割合
0.83 F H A N R
0.70 V F Q X Z
0.64 N X F G D
0.56 T N U F S
0.73 O L T R F
アルファベットのFに関しては、位置によって大きな違いがありました、しかし、これは組まされた別のアルファベットの影響も受けるわけですから、一概に言えないものになります。